În numărul anterior am prezentat Restricted Boltzmann Machines, care au fost introduse de Geoffrey Hinton, profesor la universitatea din Toronto în 2006 ca o metodă de a face ca antrenarea rețelelor neuronale să fie mult mai rapidă. În 2007, Yoshua Bengio, profesor la universitatea din Montreal, a venit cu o alternativă la RBM-uri: autoencodere.
Autoencoderele sunt rețele neuronale care învață să comprime și să proceseze datele lor de intrare. În urma procesării, din datele de intrare se extrag trăsături care sunt mai relevante și care permit o rezolvare mai ușoară a problemei de învățare automată pe care o avem, de exemplu de a clasifica imagini în funcție de conținutul lor.
De obicei, autoencoderele au cel puțin trei straturi:
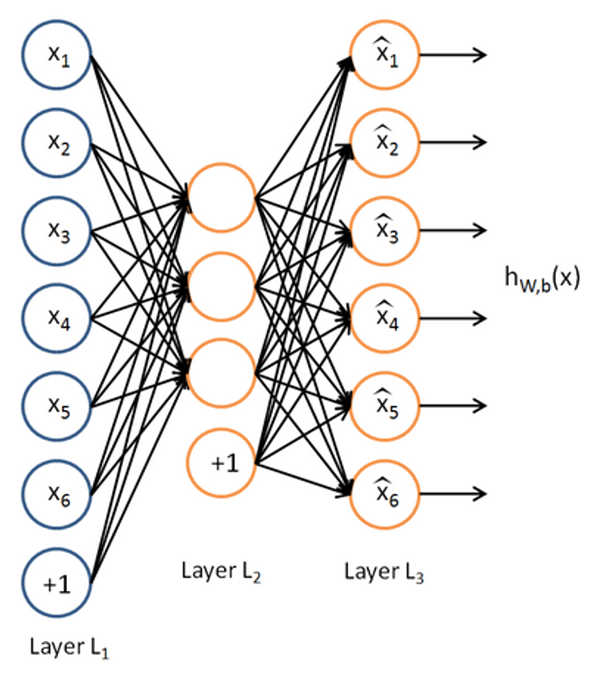
La autoencodere, valorile de ieșire sunt setate să fie egale cu cele de intrare (y = x). În mod normal, funcția cea mai simplă care realizează această "transformare" este funcția identitate, f(x) = x.
De exemplu, dacă avem un strat de intrare cu 100 de intrări, dar pe stratul interior avem doar 50 de neuroni, atunci rețeaua neuronală va trebui să comprime datele de intrare, pentru că altfel nu are o putere de reprezentare suficientă pentru a reproduce toate cele 100 de intrări în mod corect. Dacă datele noastre de intrare sunt complet aleatorii, atunci va eșua, deoarece aceasta este o problemă imposibil de rezolvat din punct de vedere al teoriei informației. Dar dacă datele de intrare au o structură, de exemplu sunt pixelii unei imagini de 10x10, atunci putem vorbi deja de o reprezentare mai compactă a pixelilor. Dacă un anumit pixel dintr-o imagine este verde, atunci de obicei cei 8 pixeli din jurul lui sunt tot verzui. Dacă observăm că anumiți pixeli de aceeași culoare sunt dispuși pe un cerc, în loc de a memora fiecare poziția fiecărui pixel (pentru un cerc cu raza de 4 pixeli,aceasta ar presupune vreo 25 de intrări), este suficient să știm că la poziția x,y avem un cerc cu raza r, care reprezintă deja doar 3 intrări.
Desigur, o comprimare așa mare nu se va realiza din prima. Dar dacă punem autoencoder peste autoencoder, într-un mod similar cu ceea ce făceam în Deep Belief Networks cu Restricted Boltzmann Machines, vom obține succesiv trăsături tot mai compacte.
Dacă privim un strat ca o funcție care primește un vector de date și returnează un alt vector, prelucrat, atunci într-un autoencoder cu 3 straturi avem 2 funcții (primul strat, cel vizibil, doar trimite mai departe intrările sale).
Prima funcție va codifica intrările sale:
h=f(x)=sf(Wx+bh)
unde sf este o funcție de activare nelineară folosită de stratul ascuns, iar W și bh sunt ponderile legăturilor dintre stratul vizibil și cel ascuns, respectiv pragurile de activare neuronii din stratul ascuns.
A doua funcție va realiza o decodificare a datelor codificate de stratul intermediar:
y = g(h) = sg(W"x+by)
unde constantele au semnificații similare, doar că între stratul ascuns și stratul de ieșire de această dată.
Combinația celor două funcții se dorește a fi funcția identitate, dar noi putem folosi apoi doar funcția de codificare, prelucrând datele noastre cu aceasta și obținând în acest fel o reprezentare de nivel mai înalt.
Cuantificarea diferenței față de funcția de identitate se face cu ajutorul erorii de reconstruire, definită astfel:
L(x, y) = ||x-y||2
Parametrii autoencoderului se aleg astfel încât această normă pătratică să fie minimală.
Modelul prezentat mai sus este cel al unui autoencoder clasic, în care învățarea trăsăturilor relevante se face prin comprimarea datelor, datorită faptului că stratul intermediar are mai puțini neuroni decât stratul de intrare.
Există și alte tipuri de autoencodere, unele dintre ele având chiar mai mulți neuroni pe stratul intermediar decât pe stratul de intrare, dar care evită problema memorării intrărilor prin alte metode.
Autoencoderele rare (sparse autoencoders) încearcă să constrângă neuronii din stratul ascuns să fie activați cât mai puțin. Neuronii din stratul ascuns sunt activați atunci când trăsăturile pe care le reprezintă sunt prezente în datele de intrare. Dacă fiecare neuron este activat rar, înseamnă că fiecăruia îi corespund trăsături diferite, semnificative. Aceasta se realizează în practică prin adăugarea unui termen de penalizare pentru numărul de activări al fiecărui neuron, pe datele de intrare pe care le avem:

unde β este un parametru ce controlează gradul de intensitate a penalizărilor activărilor dese, ρj este media activărilor neuronului j, iar ρ este parametrul de raritate și reprezintă frecvența intențiilor de a activa fiecare neuron. De obicei are o valoare sub 0.1.
Denoising autoencoders urmează o altă abordare. Atunci când este antrenat, unele valori din datele de intrare sunt corupte fie prin adăugarea unei valori mici aleatorii, fie prin aplicarea unei măști binare, care lasă neschimbate unele valori, iar pe altele le face 0. Cum rezultatul rămâne neschimbat (valorile originale), rețeaua neuronală trebuie să învețe să reproducă valorile corupte din valorile neschimbate. Pentru a face aceasta, ea trebuie să învețe ce corelări există între datele de intrare și să le aplice când vreuna din date este schimbată. Procesul de antrenare și funcția de cost sunt neschimbate.
O altă variantă de autoencodere sunt contractive autoencoders. Acestea încearcă să învețe trăsături eficiente penalizând sensibilitatea rețelei față de intrările ei. Sensibilitatea reprezintă variația rezultatului când intrarea puține modificări . Cu cât sensibilitatea este mai mică, cu atât mai mult se vor extrage aceleași trăsături și pentru intrări care se caracterizează prin mici diferențe, ceea ce este un lucru dorit. Să ne imaginăm, de exemplu, problema recunoașterii de cifre scrise de mână. Unii oameni fac cifra 0 mai turtită, alții mai alungită, alții mai rotunjită, dar diferențele totuși rămân mici, de câțiva pixeli. Noi am vrea ca rețeaua noastră să învețe aceleași trăsături pentru cât mai multe variații ale datelor de intrare. Penalizarea sensibilității se face cu norma Frobenius a Jacobianului funcției dintre stratul de intrare și cel intermediar:

Toate aceste modele pot fi combinate, desigur. Putem impune condiții atât de raritate, cât și de corupere a datelor de intrare. A detecta care dintre aceste tehnici este cea mai utilă, depinde în mare parte și de natura datelor noastre, așa că trebuie experimentat cu diferite tipuri.
Mai sunt și alte tipuri, cum ar fi Transforming Autoencoders sau Saturating Autoencoders, asupra cărora nu se va insista. Intenția este de a arăta cum se pot folosi autoencoderele cu ajutorul Pylearn2, o librărie de Python, dezvoltată de grupul de cercetare LISA de la University of Montreal. Cu ajutorul acestei librării s-au dezvoltat multe din rezultatele care au doborât recorduri în acest domeniu, mai ales legate de prelucrarea imaginilor.
În Pylearn2, modelele de deep learning pot fi configurate cu ajutorul unui fișier YAML, care apoi va fi executat de către scriptul train.py din librărie, care rulează antrenarea și apoi salvează rețeaua neuronală antrenată într-un fișier pickle.
!obj:pylearn2.train.Train {
dataset: !pkl: "cifar10_preprocessed_train.pkl",
model: !obj:pylearn2.models.autoencoder.ContractiveAutoencoder {
nvis : 192,
nhid : 400,
irange : 0.05,
act_enc: "tanh",
act_dec: "tanh",
},
algorithm: !obj:pylearn2.training_algorithms.sgd.SGD {
learning_rate : 1e-3,
batch_size : 500,
monitoring_batches : 100,
monitoring_dataset : !pkl: "cifar10_preprocessed_train.pkl",
cost : !obj:pylearn2.costs.autoencoder.MeanSquaredReconstructionError {},
termination_criterion : !obj:pylearn2.termination_criteria.MonitorBased {
prop_decrease : 0.001,
N : 10,
},
},
extensions : [!obj:pylearn2.training_algorithms.sgd.MonitorBasedLRAdjuster {}],
save_freq : 1
}
Autoencoderele reprezintă o metodă de a lua un set de date și de a-l transforma într-un alt set de date, posibil mai comprimat, care reprezintă mai bine proprietățile datelor. Pornind de aici, se poate ajunge mai ușor la rezolvarea problemei noastre, fie că este de clasificare, cluster-izare, sau regresie.
În următorul număr, vom prezenta îmbunătățirile aduse de Deep Learning la nivelul straturilor și alte tipuri noi de straturi.
de Ovidiu Mățan









