După cum am menționat anterior în această lucrare, rulăm Klocwork Insight peste nucleul Linux (versiunea 2.6.32.9) și analizăm rezultatele analizei noastre. Versiunea Klocwork Insight utilizată pentru această analiză a fost 9.2.0.6223. Figura 3 arată verificatorii Klocwork pe care i-am utilizat pentru a analiza codul sursă C/C++. Acestea sunt de fapt ,,familii de verificatori″ sau ,,categorii″, deoarece fiecare dintre aceste 3 elemente (din figura 3) conține un număr de verificatori individuali.
Acești verificatori au fost validați pe Klocwork pentru analiza noastră pentru a identifica toate problemele semnificative din codul sursă care este analizat. Metricile proiectului raportate de Klocwork după analizarea codului Linux kernel (2.6.32.9) sunt indicate în tabelul 1.
TABELUL 1
METRICILE PROIECTULUI RAPORTATE PENTRU SCA A NUCLEULUI LINUX
|
Număr total de fișiere |
13999 |
|
Număr total de fișiere C/C++ analizate |
13868 |
|
Număr total de fișiere de sistem analizate |
131 |
|
Total linii de cod (Sursă LOC) |
4309863 |
|
Total linii de comentarii |
1358746 |
|
Număr total de entități |
944835 |
|
Număr total de funcții / metode |
162814 |
|
Numărul total al claselor / tipurilor |
42797 |

În următoarele două secțiuni vom prezenta analiza vulnerabilității și analiza complexității nucleului Linux, după efectuarea SCA pe codul Linux kernel.
Anumiți identificatori ai Vulnerabilităților și Expunerilor Comune (CVE) pentru vulnerabilitățile de securitate a informațiilor publice pentru numeroase versiuni ale Linux kernel, inclusiv versiunea 2.6.32.9 sunt prezentați în tabelul 2. Vulnerabilitățile enumerate în tabelul 2 nu sunt în nici un caz complete, ci sunt o submulțime a vulnerabilităților publicate în National Vulnerability Database (NVD), după lansarea versiunii 2.6.32.9 a nucleului Linux. Lansarea versiunii 2.6.32.9 a nucleului Linux a fost anunțată în februarie ٢٠١٠. Vulnerabilitățile enumerate în tabelul ٢ au fost publicate în NVD între lunile februarie ٢٠١٠ și iulie ٢٠١١, ceea ce constituie perioada noastră de luare de probe. NVD este depozitul guvernului Statelor Unite de date de management al vulnerabilităților bazat pe standarde, reprezentate prin Security Content Automation Protocol (SCAP). Aceste date permit automatizarea managementului vulnerabilității , măsurarea securității și conformitatea. NVD include baze de date ale tabelelor de control securitate, defecte software legate de securitate, configurații greșite, nume de produse și metrici de impact (13).
Prin efectuarea SCA pe versiunea Linux kernel anterior menționată, noi putem identifica vulnerabilitățile prezentate în tabelul 2. Mai mult, aceste vulnerabilități identificate folosind SCA reprezintă aproximativ 10% din toate vulnerabilitățile Linux kernel (v2.6.32.9) raportate între februarie 2010 (lansarea versiunii Linux kernel 2.6.32.9) și iulie 2011 (sfârșitul perioadei noastre de probă) în NVD. Chiar dacă nu toate vulnerabilitățile publicate în NVD care corespund versiunii 2.6.32.9 a Linux kernel au putut fi detectate numai prin analiza statică, procentul de 10% din probleme, pe care SCA a fost în stare să le identifice, după cum arată tabelul 2, include un număr semnificativ de probleme de securitate și calitate. Din acest 10% vulnerabilități, aproximativ 22.3% au fost clasificate drept ,,Ridicate″, 44.3% au fost considerate ,,Medii″ și 33.3% au fost apreciate drept ,,Scăzute″ pe Sistemul de Evaluare al Vulnerabilităților Comune (CVSS). Acest exercițiu indică cu succes faptul că anumite vulnerabilități (după cum se arată în tabelul 2) din nucleul Linux (inclusiv versiunea 2.6.32.9), publicate încă din iulie 2011 în NVD, ar fi putut fi detectate mult mai devreme, dacă s-ar fi efectuat mai devreme o analiză statică și o revizuire sârguincioasă.
Un alt factor important de luat în considerare este tipul vulnerabilităților care pot fi identificate prin SCA. Tipurile de vulnerabilități pe care SCA a reușit să le detecteze în experimentul nostru includ buffer overflows, integer overflows/underflows, eroare integer signedness și inițiere memorie necorespunzătoare. Acestea sunt câteva din vulnerabilitățile care au fost exploatate frecvent pentru a lansa atacuri malițioase asupra diverselor aplicații software. De exemplu, anomaliile buffer overflow au o tradiție în a fi exploatate de către viruși ai computerelor precum virusul Morris (1988) sau mai recent virusul Conficker (2008). Merită efortul de a identifica asemenea viruși de timpuriu atunci când incorporăm cod opensource în codul patentat, de vreme ce experimentul nostru demonstrează că SCA are capacitatea de a detecta un număr semnificativ de astfel de viruși și este un factor motivant puternic să efectuezi SCA pe codul opensource adoptat.
TABELUL II. VULNERABILITĂȚILE LINUX KERNEL DETECTATE DE SCA
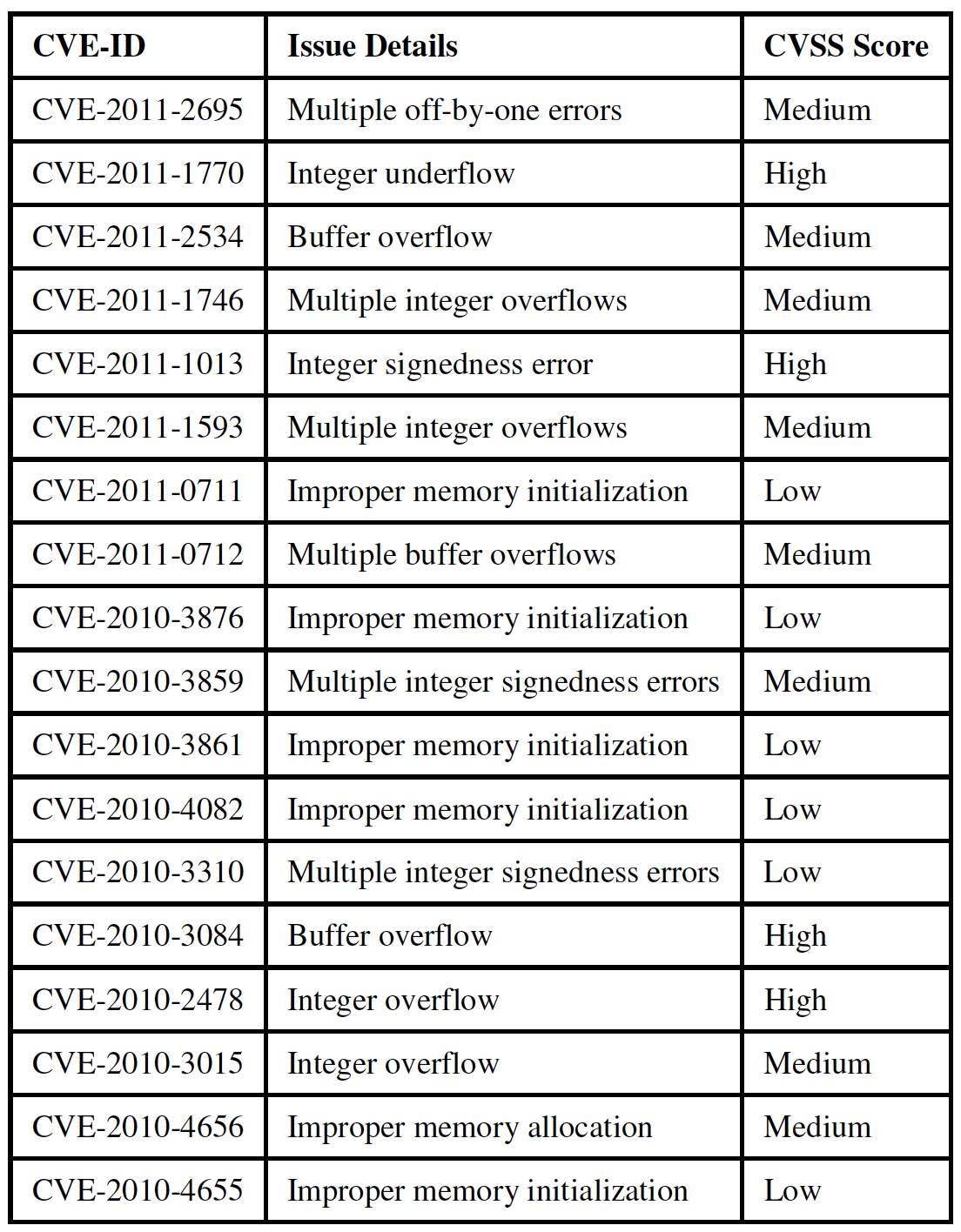
Dincolo de faptul că a reușit să detecteze aceste vulnerabilități cunoscute dinainte, instrumentul SCA a fost capabil să semnaleze anumite probleme critice din cod, care ar putea necesita o investigare suplimentară pentru a evalua veridicitatea lor și gradul în care pot fi exploatate. Chiar dacă exploatabilitatea unora dintre aceste vulnerabilități nu poate fi justificată numai prin analiza statică, este în interesul oricărui vânzător de software să rezolve aceste probleme înainte ca software-ul să fie lansat pe piață. Acest lucru stabilește importanța efectuării SCA pe codul sursă pentru a identifica și repara anumite probleme de codare de timpuriu, spre deosebire de a aștepta comunitatea opensource să identifice și să raporteze aceste probleme, deoarece, cu cât o vulnerabilitate sau un virus pot fi detectate mai devreme, cu atât mai ieftin este să le repari.
Pentru a analiza ce componente ale nucleului Linux au mai mare incidența de vulnerabilități raportate, separăm fișierele nucleului în șase categorii importante, care sunt următoarele (12):

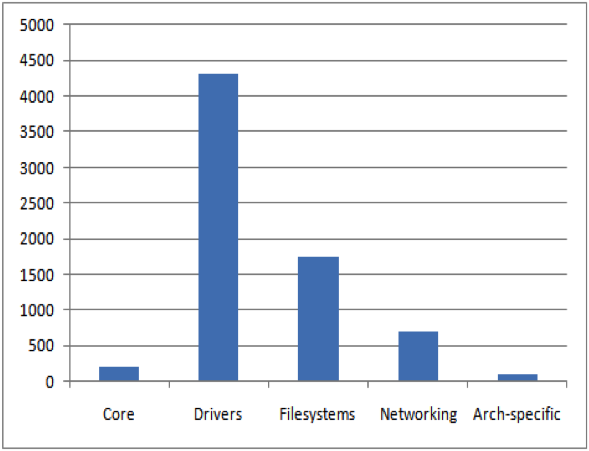
O privire rapidă peste NVD arată că cele mai multe vulnerabilități publicate (între anii 2010 și 2011) pentru nucleul Linux au loc în componentele ,,networking″ ale nucleului, urmate de componentele ,,drivere″ și ,,filesystems″, după cum se poate vedea în Figura 4. Acest lucru poate fi atribuit faptului că grupul network, care, bineînțeles, are de a face cu capacitățile de networking, este unul dintre componentele cel mai frecvent exploatate ale nucleului Linux. Acest lucru este compatibil cu ,,propunerea atrăgătoare″ de a lansa atacuri izolate și, de aceea, mulțimea network este o țintă obișnuită pentru exploatare, ceea ce ar putea justifica numărul crescut de vulnerabilități care sunt raportate.
De obicei, instrumentele SCA pot calcula parametrul complexității pentru programele pe care le analizează. Pe scurt, parametrul complexității măsoară numărul deciziilor care există într-un program; măsoară în mod direct numărul căilor independente liniare prin codul sursă al unui program. Cu cât există mai multe decizii posibile de luat în timpul rulării, cu atât sunt posibile mai multe direcții de date. Institutul Național al Standardelor și Tehnologiei (NIST) recomandă programatorilor să calculeze complexitatea modulelor pe care le dezvoltă și să le separe în module mai mici ori de câte ori complexitatea ciclomatică a modulului depășește 10. Dar în anumite circumstanțe, poate fi adecvată lărgirea restricției și îngăduirea modulelor cu o complexitate până la 15, dacă este oferită o explicație în scris a motivelor pentru care a fost depășită limita (9). Un parametru ridicat de complexitate face aproape imposibil ca un programator uman să poată urmări toate căile posibile, iar de aici rezultă probabilitatea crescută ca programatorul să introducă un defect nou atunci când codul este modificat sau când se adaugă cod nou. Dacă complexitatea ciclomatică a programului este mai mare de 50, un asemenea program este considerat ne-testabil și având un risc foarte mare. Studiile arată o corelare între complexitatea ciclomatică a programului și mentenabilitatea și testabilitatea sa, sugerând că la fișierele cu complexitate mai mare există o probabilitate mai mare de erori atunci când se repară, se îmbunătățește sau se reutilizează codul sursă. Într-un proiect opensource similar lui Linux, cea mai mare parte a efortului de dezvoltare este comunicată prin liste de adrese. Dezvoltatorii sunt împrăștiați în jurul lumii și prezintă niveluri variate de abilități de dezvoltare software. De aceea, această situație ar putea reprezenta o sarcină provocatoare pentru orice entitate centrală responsabilă cu coordonarea eforturilor de dezvoltare.
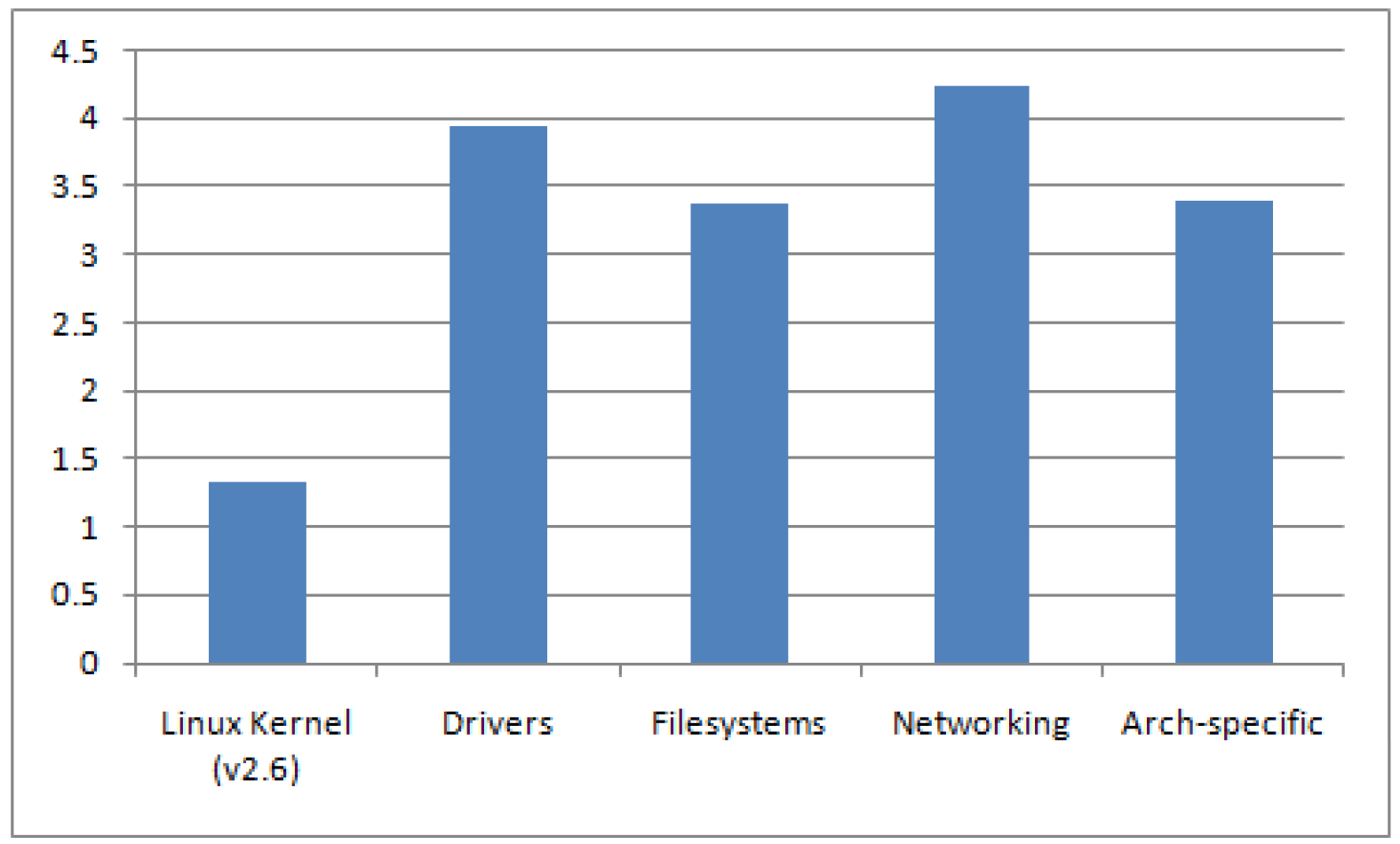
Numărul metodelor cu o complexitate mai mare de 20 conținute în componentele nucleului Linux este ilustrat în figura 5. Raportul de complexitate medie (Complexitatea maximă a metodelor / Numărul total de metode) pentru metodele cu o complexitate mai mare de 20 per categorie semnificativă a nucleului Linux este ilustrat în figura 6. Prima coloană din figura 6 reprezintă complexitatea medie pentru întregul nucleu Linux (v2.6.32.9), în timp ce restul coloanelor reprezintă complexitatea medie pentru componentele semnificative conținute de nucleul Linux. Din figura 6 reiese în mod evident faptul că complexitatea medie pentru componentele individuale importante din Linux kernel este mult mai mare (peste 2x) decât complexitatea medie pentru întregul Linux kernel. O privire rapidă prin NVD arată că cele mai multe vulnerabilități publicate pentru nucleul Linux se găsesc în componentele care conțin un număr mare de metode de complexitate crescută care cel mai adesea includ componentele ,,drivers″, ,,filesystems″ și ,,networking″, după cum se arată în Figura 4.
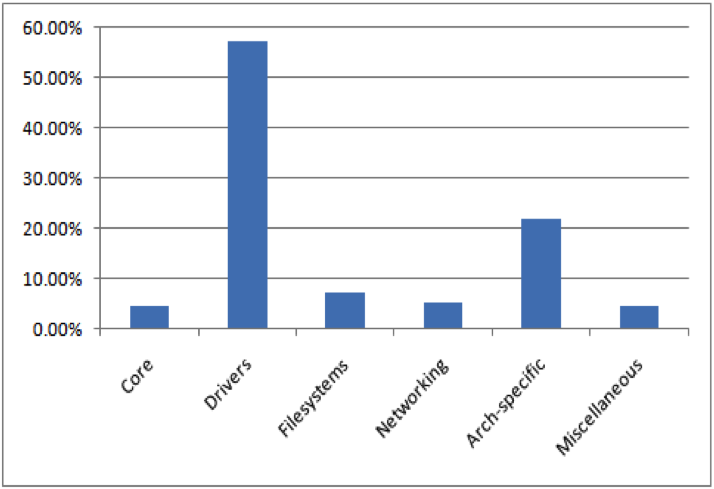
Mărimea procentului per categorie semnificativă din nucleul Linux (versiunea 2.6) este ilustrată în figura 7. Numărul de linii modificate per categorie importantă din nucleu Linux (versiunea 2.6) este arătat în figura 8. Este interesant de observat că, în ciuda faptului că componenta ,,networking″ a nucleului Linux conține un număr mai mic de metode de complexitate ridicată ( din figura 5) și mai puține Linii de Cod (LOC) (din figura 7) în comparație cu componentele ,,drivers″ și ,,filesystems″, o majoritate a vulnerabilităților publicate în NVD au loc în componenta ,,networking″ (din figura 4). Motivul pentru aceasta a fost discutat în secțiunea anterioară despre analiza vulnerabilității. Mai mult, chiar dacă componenta ,,networking″ a nucleului Linux conține mai puține linii de cod, complexitatea medie (din fig.6) pentru componenta ,,networking″ este cea mai ridicată în comparație cu alte componente ale Linux kernel, ceea ce sugerează că componentele ce au o complexitate ridicată tind să conțină un număr mai mare de erori. Un alt lucru interesant de notat se referă la componenta ,,architecture-specific″ a nucleului Linux care are un număr mai mic de metode de complexitate ridicată (din fig.5), are mai multe linii de cod (din fig.7) și a suferit un număr important de modificări în liniile de cod (din fig.8). În plus, complexitatea medie (din fig.6) pentru componenta ,,architecture-specific″ este ridicată, ceea ce sugerează că acele componentele care primesc un număr mare de modificări în liniile de cod tind să aibă o complexitate mai mare.
În general, din analiza noastră, observăm următoarele tipare:
• Probabilitatea ridicată de erori în componentele cu o complexitate mai mare (din fig. 4, 5 și 6), de exemplu componentele ,,drivers″, ,,filesystems″ și ,,architecture-specific″.
• Componentele complexe cu un număr mai mare de linii de cod au primit un număr mai mare de modificări de cod și actualizări (din fig.7 și 8), de exemplu componentele ,,drivers″ și ,,architecture-specific″.
• Componentele critice, cum ar fi ,,networking″, tind să prezinte incidențe mai mari de erori raportate (din fig. 4).
Prin observarea acestor tipare, am putea să concentrăm aria de acoperire a SCA asupra acestor componente critice ale codului, ceea ce vom explica în secțiunile următoare.
de Ovidiu Mățan









