În ziua de astăzi, când vine vorba de site-uri uriașe, problema performanței apare des, împreuna cu întrebarea "Noi cum putem deservi așa o masă mare de clienți la un preț rezonabil ? ". Ei bine, unul dintre cele mai mari site-uri de pe planetă, Facebook, au un răspuns destul de bun: HipHop Virtual Machine. Ce e acest soft, cum s-a născut, cum funcționează și de ce e mai bun ca alternativele ?
Toate aceste întrebări voi încerca să le răspund în paginile care urmează. Informațiile prezente în acest articol sunt împrăștiate prin multe documente, interviuri, bloguri, wiki-uri etc..Acest articol încearcă să ofere o imagine de ansamblu asupra acestui proiect. Țineți cont că unele aspecte și funcționalități nu vor fi abordate decât foarte vag,iar altele,deloc. Dacă doriți informații detaliate despre o anumită funcționalitate, vă invit să consultați documentația sau blogul dedicat acestui proiect.
Mașina virtuală HipHop este un motor de execuție a codului PHP. A fost creată de către Facebook în încercarea de a economisi resurse computaționale pe webserver-ele lor, care deveneau din ce în ce mai solicitate de numărul tot mai mare de vizitatori.
Istoria începe în vara anului 2007 când Facebook a început dezvoltarea lui HPHPc. Modul de funcționare a lui HPHPc era următorul:
În vremurile lui de glorie, HPHPc a reușit să obțină în unele cazuri performanțe cu până la 500 % mai mari decât platforma Zend (platforma PHP obișnuită).
Aceste rezultate impresionante au convins inginerii de la Facebook că HPHPc merită păstrat și îmbunătățit. Aceștia au decis să-i dea și un frate: HPHPi (HipHop interpreted). HPHPi este varianta "developer-friendly" a lui HPHPc și, pe lângă eliminarea pasului de compilare, acesta oferă utilități pentru programatori, printre care un code debugger numit HPHPd, analiza statică a codului, performance profiling și multe altele. Cele două produse (HPHPc și HPHPi) au fost dezvoltate și menținute în paralel pentru a păstra compatibilitatea dintre ele.
Dezvoltarea lui HPHPc a durat doi ani, iar la sfârșitul lui 2009, acesta motoriza 90 % din server-ele din producție ale site-ului. Performanța era excelentă, load-ul pe servere a scăzut simțitor (50 % în unele cazuri) și toată lumea era fericită. Așa că, în februarie 2010, codul sursă a lui HPHPc a devenit open-source și a fost publicat pe GitHub sub licența PHP License.
Dar inginerii de la Facebook și-au dat seama că performanța superioară nu avea să garanteze succesul lui HPHPc pe termen lung. Iată de ce:
Așa că, la începutul lui 2010 (chiar după ce HPHPc a devenit open-source) Facebook a format o echipă care să cerceteze și să vină cu o alternativă viabilă la HPHPc, una care să poată fi menținută pe termen lung. O mașină virtuală care folosește un compilator JIT părea să fie răspunsul iar încarnarea acestei alternative a dat naștere lui HipHop Virtual Machine (HHVM).
La început, HHVM-ul a înlocuit doar HPHPi-ul și a fost folosit doar pentru development, HPHPc rămânând în producție. Însă, la sfârșitul anului 2012, HHVM-ul a depășit în performanță HPHPc și, prin urmare, în februarie 2013, toate server-ele din producție ale Facebook-ului au fost trecute pe HHVM.
II. Arhitectura
Arhitectura generală a HHVM-ului e formată din două webserver-e, un translator, un compilator JIT și un garbage collector.
HHVM-ul nu rulează pe orice sistem de operare. Mai exact:
HHVM-ul va rula doar pe sisteme de operare pe 64 de biți. Conform echipei de ingineri, suportul pentru sisteme de operare pe 32 de biți nu va fi introdus niciodată.

Pașii generali de funcționare ai HHVM-ului sunt următorii:
Detalii despre pașii menționați mai sus puteți găsi în secțiunile următoare.
HHVM-ul ține bytecode-ul (HHBC) într-un cache implementat sub forma unei baze de date SQLite. Când HHVM-ul primește un request, trebuie să determine care fișier PHP să-l execute. După ce a facut aceasta, va verifica cache-ul pentru a determina dacă are deja bytecode-ul pentru acel fișier și dacă acel bytecode e actualizat.
Dacă bytecode-ul există și e actualizat, va fi executat. Un bytecode executat cel puțin o dată va fi păstrat și în RAM. Dacă însă acesta nu există sau dacă fișierul PHP a fost modificat de la ultima generare a bytecode-ului, atunci acesta va fi recompilat și bytecode-ul lui va fi reintrodus în cache. Acest mod de operare e practic identic cu cel al APC-ului (Apache PHP Cache).
Acest comportament înseamnă că, la prima execuție a fiecărui fișier, există o perioadă semnificativă de warm-up. Vestea bună e că HHVM-ul păstrează cache-ul pe disk; asta înseamnă că, spre deosebire de APC, el va supraviețui dacă HHVM-ul sau webserver-ul fizic e restartat. Deci perioada de warm-up nu va trebui repetată.
Chiar și așa, perioada de warm-up poate fi ocolită în totalitate. Acesta se poate face prin așa numita pre-analiză. Acest lucru înseamnă că cache-ul poate fi pre-generat înainte de a porni HHVM-ul. După instalarea HHVM-ului, există un executabil în pachet cu ajutorul căruia se poate genera bytecode-ul pentru întregul cod sursă al site-ului și introdus în cache. În acest fel, la pornirea HHVM-ului, cache-ul e deja umplut și gata de folosire.
Trebuie ținut cont de faptul că cheile de cache conțin, printre altele, build-ID-ul HHVM-ului. Deci dacă HHVM-ul va fi înlocuit cu o versiune mai nouă sau mai veche, conținutul cache-ului se va pierde și va trebui re-generat.
Un mod interesant de rulare a HHVM-ului este modul RepoAuthoritative. După cum am zis în secțiunea despre cache, HHVM-ul va verifica la fiecare request dacă fișierul PHP cerut a fost modificat de la ultima sa compilare. Aceasta înseamnă operațiuni de disk IO care, din câte se știe, sunt scumpe din punct de vedere computațional. Durează doar o fracțiune de secundă, dar e o fracțiune de secundă pe care n-o avem atunci când încercăm să deservim mii de request-uri pe minut.
Când modul RepoAuthoritative e activat, HHVM-ul nu va mai verifica dacă fișierul PHP a fost modificat, ci va merge direct în cache. Numele vine de la faptul că cache-ul este denumit "repo" în terminologia HHVM-ul și că acest "repo" devine autoritatea principală a codului.
Modul RepoAuthoritative se poate activa adăugând următoarele linii de cod în fișierul de configurare:
Repo {
Authoritative = true
}Trebuie avut grijă cu acest mod de rulare pentru că, dacă bytecode-ul unui fișier lipsește din cache, clientul va primi o eroare HTTP 404, chiar dacă fișierul PHP există și poate fi executat fără probleme.
Modul RepoAuthoritative este recomandat pentru sistemele din producție din două motive:
Bytecode-ul este o formă intermediară de cod care nu este caracteristică vreunui procesor sau vreunei platforme, el este prin definiție portabil. La rulare, acest bytecode este transformat în cod mașină într-un proces numit Just-In-Time compilation (JIT). Compilatorul poate să transforme în cod mașină doar o bucată de cod, o funcție, o clasă sau chiar un întreg fișier.
În general, sunt trei caracteristici ale compilatoarelor JIT care sunt importante pentru eficiența lor:
Compilatorul JIT din HHVM este bijuteria acestuia, modulul responsabil pentru tot succesul mașinii virtuale. În timp ce compilatorul JIT din mașina virtuală Java folosește metodele unei clase ca bloc unitar de compilare, compilatorul JIT din HHVM folosește așa numitele tracelet-uri.
Un tracelet e de obicei o buclă pentru că, conform cercetării, cele mai multe programe își petrec mare parte din timp într-o buclă ale cărei iterații sunt foarte asemănătoare și, prin urmare, au căi identice de rulare.
Tracelet-ul e format din trei părți:
Fiecare tracelet are libertate foarte mare în ceea ce privește instrucțiunile pe care are voie să le execute, dar trebuie ca mașina virtuală să rămână într-o stare consistentă la terminarea execuției unui tracelet.
Un tracelet are doar o singură cale de execuție: instrucțiune după instrucțiune după instrucțiune. Nu există branch-uri sau flow control. Asta le face foarte ușor de optimizat.
În cele mai multe limbaje moderne, programatorul nu e nevoit să facă management al memoriei. Trecute sunt zilele în care trebuia să te chinui cu aritmetica pointer-ilor. Felul în care o mașină virtuală (inclusiv HHVM) face management-ul memoriei se numește Garbage Collection.
Colectorii se împart în două mari categorii:
Cei mai mulți colectori sunt un hibrid al celor două metode, însă mereu una dintre ele e dominantă.
Colectorii bazați pe tracing sunt mai eficienți, mai performanți și mai ușor de implementat. Acest tip de garbage collector a fost intenționat și pentru HHVM dar, cum PHP-ul necesită un colector pe bază de refcounting, inginerii HHVM-ului au fost nevoiți să renunțe la idee, cel puțin temporar.
PHP-ul are nevoie de un colector de tip refcounting pentru că:
Inginerii HHVM-ului își doresc foarte mult să facă trecerea către un garbage collector pe bază de tracing. Au și încercat la un moment dat; însă, datorită restricțiilor menționate mai sus, codul a devenit foarte complicat și ceva mai lent, așa că au renunțat. Sunt totuși șanse ca acest plan să se materializeze în următorii ani.
Un ultim punct: HHVM nu are un colector ciclic (obiectul A referențiază obiectul B care referențiază obiectul A). Un astfel de colector e present în codul sursă, dar e inactiv.
HHVM-ul lucrează mai bine atunci când știe cât mai multe detalii statice despre cod înainte să-l ruleze. Având în vedere că mare parte din codebase-ul Facebook-ului este scris în stil orientat pe obiect, HHVM-ul se va descurca mai bine cu astfel de cod.
Mai concret, e indicat să se evite:
Atunci când e posibil, e bine să se specifice:
De asemenea, e bine de știut că o compilare a codului din scopul global nu va fi niciodată realizată de către compilatorul JIT. Aceasta se întâmplă pentru că starea variabilelor din scopul global poate fi modificată de oriunde altundeva. Un exemplu luat de pe blogul HHVM-ului:
class B {
public function __toString() {
$GLOBALS["a"] = "I am a string now";
}
}
$a = 5;
$b = new B();
echo $b;
Variabilele $a și $b sunt în scop global. Atunci când se apelează echo $b, metoda __toString din clasa B e apelată. Aceasta modifică tipul variabilei $a din număr întreg în șir de caractere. Dacă variabilele $a și $b ar fi trecute prin compilatorul JIT, acesta ar deveni foarte confuz în legătură cu tipul și conținutul variabilei $a.
Prin urmare, e foarte indicat ca tot codul să fie pus în clase și funcții.
III. Facilități
După cum am zis în capitolul despre arhitectură, HHVM-ul conține două webserver-e. Unul dintre ele e webserver-ul care deservește trafic HTTP obișnuit prin port-ul 80. Al doilea se numește AdminServer și oferă acces la câteva operațiuni de administrare a HHVM-ului.
Pentru a activa AdminServer-ul, adăugați următoarea secvență de cod în fișierul de configurare:
AdminServer {
Port = 9191
ThreadCount = 1
Password = mypasswordhaha
}AdminServer-ul se poate apoi accesa la adresa:
http://localhost:9191/check-health?auth=mypasswordhahaOpțiunea "check-health" din URI-ul de mai sus e doar una dintre opțiunile suportate de către AdminServer. Alte opțiuni permit afișarea de statistici legate de trafic, query-uri, memcache, încărcarea procesorului, numărul de thread-uri active și multe altele. Se poate inclusiv opri webserver-ul principal de aici.
Una dintre cele mai așteptate facilități este suportul pentru FastCGI. Acesta a fost introdus în versiunea 2.3.0 a HHVM-ului (decembrie 2013) și e un protocol de comunicare suportat de cele mai populare webserver-e, cum ar fi Apache sau nginx. Suportul pentru acest protocol înseamnă că nu mai e nevoie să folosim webserver-ul încorporat în HHVM, ci putem folosi de exemplu Apache ca webserver și să lăsăm HHVM-ul să făcă ce știe mai bine: să execute cod PHP cu mare viteză.

Această facilitate e una crucială pentru că va garanta creșterea popularității HHVM-ului.
HHVM-ul are suport experimental pentru extensiile scrise pentru Zend PHP. Acest suport e obținut folosind un așa numit PHP Extension Compatibility Layer. Scopul acestui layer este să ofere acces la același API și macro-uri ca și PHP, altfel extensiile nu vor funcționa.
Pentru ca o extensie PHP să funcționeze, trebuie re-compilată folosind implementarea HHVM-ului a respectivului API. De asemenea, trebuie compilată drept cod C++, nu C. Aceasta presupune de obicei modificări minore ale codului extensiei.
HHVM suportă și extensii terțe, la fel ca Zend PHP. Ele pot fi scrise în PHP sau C++. Extensia va fi apoi adăugată în codul sursa al HHVM-ului ,iar întregul HHVM va fi recompilat. Noul executabil al HHVM-ului va conține extensia ,iar funcționalitatea oferită de aceasta va putea fi accesată în codul rulat.
HHVM-ul include deja cele mai populare extensii, cum ar fi: MySQL, PDO, cURL, PHAR, XML, SimpleXML, JSON, memcache și multe altele. Momentan nu este inclusă extensia MySQLi.
IV. Cod suportat
HHVM-ul pare a fi un produs solid, robust, rapid. Dar toate acestea nu ar conta deloc dacă HHVM-ul nu ar putea rula cod real din lumea reală. Inginerii HHVM-ului măsoară abilitatea aceasta prin rularea pe HHVM a unit-test-elor celor mai populare 20 de framework-uri și aplicații PHP, printre care Symfony, phpBB, PHPUnit, Magento, CodeIgniter, phpMyAdmin și multe altele.
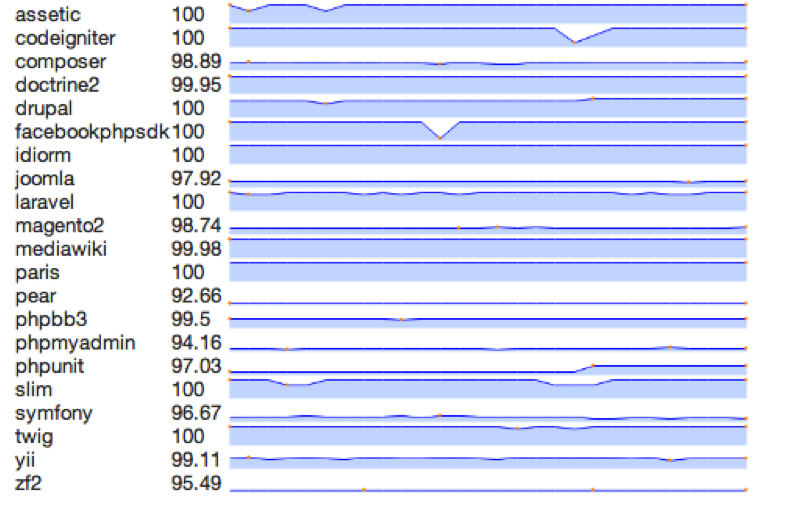
Cifrele din dreptul fiecarei aplicații reprezintă procentajul unit-test-elor care sunt executate cu succes. Inginerii HHVM-ului îmbunătățesc aceste cifre la fiecare release și speră că toate unit-test-ele acestor aplicatii să treacă în cel mult un an.
În lumea reală, se știe că următoarele site-uri folosesc HHVM pentru a rula:
Multe din site-urile care folosesc HHVM vor trimite header-ul X-Powered-By: HPHP ca răspuns.
V. Concluzie
În concluzie, HHVM-ul este un produs revoluționar, robust, rapid care se dezvoltă constant și, datorită suportului pentru FastCGI, se răspândește repede. Foarte multe concepte și soluții folosite de HPHPc și HHVM au fost introduse în Zend PHP. Este și motivul pentru care sunt așa de mari îmbunătățiri de performanță de la PHP 5.2 la PHP 5.5.
de Ovidiu Mățan









