După ce în articolul trecut am prezentat pe scurt istoria deep learning-ului și am enumerat câteva dintre tehnicile care se folosesc, acum voi oferi detalii despre părțile componente ale unui sistem de deep learning.
Deep learning a obținut primul succes în 2006, când Geoffrey Hinton și Ruslan Salakhutdinov au publicat articolul "Reducing the Dimensionality of Data with Neural Networks", care a fost prima aplicare eficientă și rapidă a mașinilor Boltzmann restrânse (Restricted Boltzmann Machines sau, pe scurt, RBM).
După cum sugerează și numele, RBM-urile sunt un fel de mașini Boltzmann, cu anumite constrângeri. Acestea au fost propuse de Geoffrey Hinton și Terry Sejnowski în 1985 și au fost primele rețele neuronale care puteau să învețe reprezentări interne (modele) ale datelor de intrare și să se folosească de aceasta pentru a rezolva apoi diferite probleme, cum ar fi completarea de imagini incomplete. Ele nu au fost folosite multă devreme deoarece, în lipsa unor constrângeri, algoritmul de învățare a reprezentării interne era foarte ineficient.
Conform definiției, mașinile Boltzmann sunt rețele neuronale recurente stochastice generative. Stochasticitatea lor înseamnă că au un element probabilistic în ele și neuronii din rețea nu sunt activați în mod deterministic, ci cu o anumită probabilitate, în funcție de intrările lor. Faptul că sunt generative înseamnă că învață distribuția de probabilitate a variabilelor de intrare și construiesc un model pentru acestea, care poate fi folosit apoi pentru a genera alte date aleatorii, similare celor cu care au fost antrenate.
Dar există și un alt mod de a privi mașinile Boltzmann, ca fiind modele grafice bazate pe energie. Aceasta înseamnă că fiecărei combinații de date de intrare asociem un număr, numit "energie", iar pentru combinațiile pe care le avem între datele de intrare dorim ca energia să fie cât mai mică, iar pentru toate celelalte să fie cât mai mare.
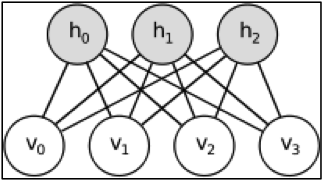
Constrângerea impusă asupre RBM-urilor este că neuronii trebuie să formeze un graf bipartit, ceea ce în practică înseamnă că nu există legături între neuronii din stratul vizibil, nici între neuronii din stratul ascuns, ci doar între cele două straturi. În figura de alături se observă că nu avem conexiuni între v-uri, nici între h-uri, ci doar între fiecare v cu fiecare h.
Stratul ascuns din RBM se poate considera ca fiind factorii care generează stratul de intrare. Dacă analizăm notele date de utilizatori unor filme, atunci stratul de intrare corespunde notelor date de un utilizator la mai multe filme, iar stratul ascuns corespunde categoriilor de filme. Aceste categorii nu sunt predefinite, ci RBM-ul construiește un model intern în care grupează filmele astfel încât energia totală să fie minimizată. Dacă datele de intrare sunt pixeli ai unei imagini, atunci putem considera stratul ascuns drept trăsături ale obiectelor care generează acei pixeli (cum ar fi margini de obiecte, colțuri, linii drepte și alte trăsături care diferențiază obiectele).
Privind RBM-urile ca modele bazate pe energie, putem să ne folosim de tehnici preluate din fizica statistică ca să estimăm distribuția de probabilitate și apoi să facem predicții. De altfel, partea de Boltzmann din nume vine de la faptul că distribuția pe care o va învăța este de tip Boltzmann, o distribuție clasică din fizica statistică.
Energia unui astfel de model, știind vectorul v (stratul de intrare), vectorul h (stratul ascuns), matricea W (ponderile asociate fiecărei conexiuni dintre un neuron din stratul de intrare și cel ascuns), și vectorii a și b (care corespund pragurilor de activare specifice fiecărui neuron din stratul de intrare, respectiv stratul ascuns) este dată de următoarea formulă:

Deși pare urâtă formula, este vorba doar de adunare și înmulțire de matrici.
Odată ce avem energia pentru o stare, probabilitatea ei este dată de:

Z este un factor de normalizare, ca să dea bine probabilitățile.
Aici este unul din locurile unde constrângerile din RBM ne ajută. Pentru că neuronii din stratul vizibil nu sunt conectați între ei înseamnă că dacă fixăm neuronii din stratul ascuns, atunci neuronii din stratul vizibil sunt independenți unii de alții. Așa că putem obține ușor probabilitatea unor date de intrare pentru o valoare fixă a neuronilor din stratul ascuns:

unde

reprezintă probabilitatea de activare a unui singur neuron:


În mod analog se poate defini și probabilitatea pentru stratul ascuns, având stratul vizibil fixat.

La ce ne ajută dacă știm aceste probabilități?
Să presupunem că știm valorile corecte ale ponderilor și ale pragurilor de activare a neuronilor pentru un RBM și că vrem să vedem ce obiecte sunt într-o imagine. Punem pixelii imaginii ca fiind intrările RBM-ului și calculăm probabilitățile de activare pentru stratul ascuns. Aceste probabilități le putem interpreta drept filtre pe care le-a învățat RBM-ul despre obiectele care pot exista în imagini.
Luăm valorile probabilităților, și le introducem într-un alt RBM ca date de intrare. Acest RBM scoate și el la rândul lui alte probabilități, care sunt filtre pentru intrările lui. Aceste filtre sunt de un nivel mai înalt deja. Repetăm acest procedeu de câteva ori, punem unul peste altul RBM-urile, peste ultimul strat punem un strat de clasificare (chiar și regresia logistică funcționează bine) și obținem un Deep Belief Network.
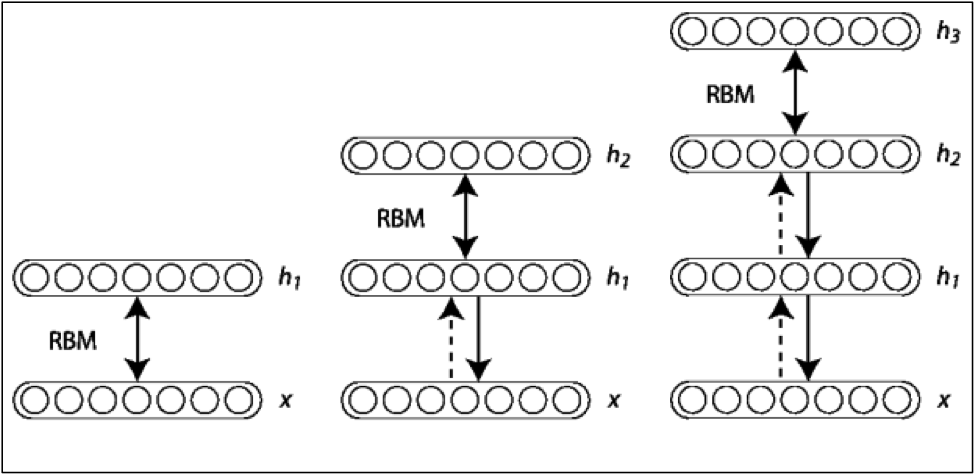
Ideea care a stat la baza revoluției deep learning a fost aceasta: că poți învăța strat cu strat filtre pentru trăsături tot mai complexe și astfel la sfârșit nu mai clasifici ce este într-o poză direct din pixeli, ci din trăsături de nivel înalt, care sunt mult mai bune indicatore pentru conținutul unei poze.
Învățarea parametrilor unui RBM se face cu un algoritm numit "contrastive divergence". Acesta pornește cu un exemplu din datele de intrare, calculează valorile pentru stratul ascuns, pentru ca din aceste valori obținute pentru stratul ascuns să se simuleze apoi ce valori de intrare au produs. Parametrii sunt apoi schimbați cu diferența dintre valoarea originală și valoarea simulată (sub formă de produs matriceal). Aceasta se repetă pentru fiecare exemplu din datele de intrare, de mai multe ori, până când fie eroarea devine suficient de mică, fie au trecut un număr predefinit de iterații.

RBM-urile sunt implementate în multe librării de învățare automată. Una dintre acestea este scikit-learn, o librărie Python care este folosită de firme cum ar fi Evernote sau Spotify pentru clasificarea notițelor sau pentru recomandare de muzică. În continuare vom prezenta ce ușor se poate antrena un RBM pe un set de imagini care conțin litere și cifre, după care vom vizualiza filtrele pe care le învață acesta.
from sklearn.neural_network import BernoulliRBM as RBM
import numpy as np
import matplotlib.pyplot as plt
import cPickle
X,y = cPickle.load(open("letters.pkl"))
X = (X - np.min(X, 0)) / (np.max(X, 0) + 0.0001) # 0-1 scaling
rbm = RBM(n_components=900, learning_rate=0.05, batch_size=100, n_iter=50)
print("Init rbm")
rbm.fit(X)
plt.figure(figsize=(10.2, 10))
for i, comp in enumerate(rbm.components_):
plt.subplot(30, 30, i + 1)
plt.imshow(comp.reshape((20, 20)), cmap=plt.cm.gray_r,
interpolation="nearest")
plt.xticks(())
plt.yticks(())
plt.suptitle("900 components extracted by RBM", fontsize=16)
plt.show()
RBM-urile sunt o componentă esențială de la care a pornit deep learning-ul și sunt unul din puținele modele care ne permit să ne construim eficient o reprezentare internă a problemei pe care dorim să o rezolvăm. În articolul următor, vom vedea o altă abordare la învățarea reprezentărilor interne, cu autoencodere.
de Cezar Coca









