În numerele trecute am descoperit lumea pe care Hadoop o formează. O lume în care fișierele de 100GB sau 500GB sunt la ordinea zilei. Acesta ne permite să facem lucruri pe care nu le puteam face până acum.
Datele pe care firma noastră le colectează pot să devină o mină de aur. Putând prelucra cantități mari de date, avem posibilitatea să vizualizăm datele într-un mod pe care nu l-am putut face până acuma.
Prima întrebare pe care trebuie să o punem când dorim să analizăm datele cu Hadoop este: Ce dorim să analizăm? Răspunsul la această întrebare este important, deoarece trebuie să identificăm ce vrem să facem cu datele, ce informație dorim să analizăm și care este valoarea acestor date.
Un scenariu simplu, este identificarea profilului unui utilizator. Putem astfel să recomandăm sau sa facem reclamă la diferite produse. Totodată prin folosirea unui sistem ca Hadoop putem să creăm un mecanism de identificare a fraudelor, prin selectarea excepțiilor de la șabloanele cunoscute.

În comparație cu restul soluțiilor care sunt pe piață, Hadoop vine cu costuri extrem de mici. Acesta nu are nevoie de hardware special pe care să ruleze. Poate să funcționeze fără nici un fel de probleme pe orice sistem, chiar dacă acesta este laptopul de acasă, server-ul de la lucru la mașina de 500.000 de euro pe care clientul a cumpărat-o. În funcție de task-ul pe care dorim îl facem un job poate să dureze de la câteva minute până la ore sau zile. Hadoop nu are nici o constrângere din acest punct de vedere, putând rula un job zile întregi fără nici un fel de probleme.
Prin abstractizarea mediului unde rulează și modului în care Hadoop este construit, se permite să facem un lucru care nu poate să fie pe orice fel de sistem de acest fel. Scalabilitatea este liniară. Aceasta înseamnă că dacă dublăm numărul de noduri o să putem înjumătăți timpul de analiză. În acest mod putem să pornim cu o configurație simplă, iar dacă volumul de date creste, putem să creștem și numărul de noduri.
Datorită acestei proprietăți, există mulți furnizori de cloud care oferă acest serviciu. Orice furnizor de cloud poate să își folosească mașinile pe care le are pentru a rula Hadoop și să scaleze numărul de mașini în funcție de necesitățile pe care clientul le are.
O povestioară destul de interesantă este cea a lui Pete Warden care a folosit Hadoop pentru a analiza profilul a 220 de milioane de utilizatori a Facebook. Acest lucru a luat doar 11 ore, iar costul a fost extrem de mic. Vă întrebați oare cât de mic? Costul final a fost de 100$. Acesta este exemplul perfect unde Hadoop își poate face treaba bine și cu costuri minime.
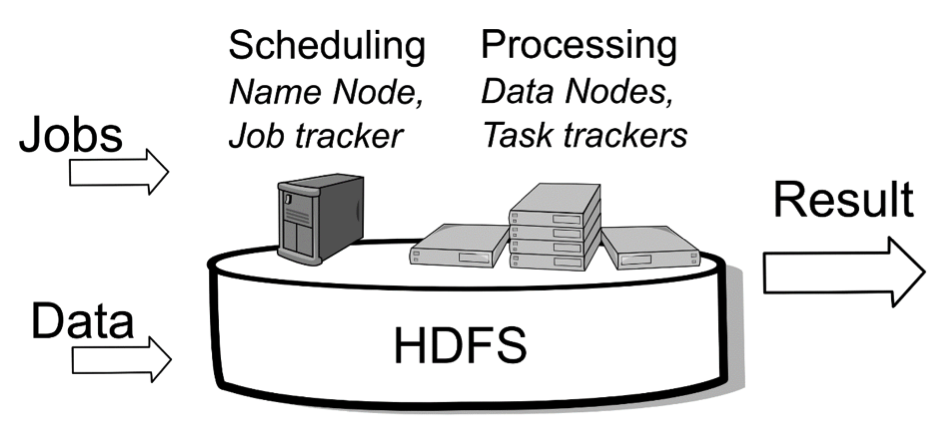
Așa cum am văzut și până acuma, arhitectura Hadoop este simplă, bazându-se pe HDFS - Hadoop Distributed File System și MapReduce.
HDSF este în stare să împartă, distribuie și să facă management la date foarte mari. Toate aceste date, odată stocate în Hadoop pot să fie procesate folosind MapReduce. În momentul în care datele sunt procesate, Hadoop nu trimite datele la nodurile care se ocupa cu procesarea. Fiecare nod din sistem care stochează datele urmează să proceseze datele pe care le stochează. În acest fel, analiza datelor se face mult mai repede, iar sistemul este mult mai scalabil.
Operația de MapReduce este o operație care se desfășoară în doua faze. În prima fază, operația de Map rulează pe fiecare nod în parte. A doua faza de analiză, care poartă numele de Reduce este opțională. Toată logica pe care noi o scriem - modul în care analizăm datele, stă in operațiile de Map și Reduce.
Logica pe care trebuie să o scriem pentru a putea scrie procesele de analiză poate să fie scrisă în diferite limbaje. Ce nu trebuie să uităm este că limbajul în care Hadoop a fost scris este Java.
Din această cauză chiar dacă putem să folosim și alte limbaje în afară de Java, cea mai bună performanță o vom obținem folosind Java. De exemplu dacă folosim Streaming API s-ar putea ca performanța să scadă cu până la 20%.

Dacă dorim să ne configurăm un sistem Hadoop, trebuie să fim pregătiți să folosim Linux. Chiar dacă acesta rulează fără nici un fel de probleme de Windows, inițial Hadoop a fost făcut să ruleze pe Linux. Cunoștințele de Linux ne vor fi folositoare în momentul în care trebuie să configurăm acest sistem. Sub Linux, Hadoop rulează pe o versiune de Linux derivată din Ubuntu și RedHat. Aceasta poartă numele de CDH - Cloudera Distribution of Hadoop. O soluție pe care o recomand la acest pas este folosirea unor imagini care au deja instalat și configurat acest sistem. Prin acest mod, în 10 minute putem să avem deja un sistem funcțional și pregătit pentru lucru.
Dacă suntem la faza de development atunci nu este recomandat să rulam codul direct pe un sistem real, deoarece procesul de debug poate să fie extrem de anevoios. În primă fază, putem să folosim Local Jobrunner Mode, care ne permite să rulăm teste de dimensiuni mici și să facem debug pe operațiile de tip Map și Reduce. Odată ce avem un cod funcțional, putem să trecem la următorul pas și să folosim Pseudo-Distributed Mode. Acest mod replica mediul real dar ne oferă câteva funcționalități pentru debug. Dacă am trecut și de acest pas cu bine, atunci putem să facem pasul final și să trecem la următorul mod Fully-Distributed Mode. Aceste este mediul nostru real, cel de producție.
Prin dezvoltarea și rularea codului în cele trei moduri, costul de dezvoltare scade, iar numărul de bug-uri pe care le găsim va fi mare.
Stilul de programare pe care trebuie să îl aplicam în momentul în care folosim Hadoop este cel de tip defensive. Trebuie să încercăm să prindem toate excepțiile cu putință și să le tratăm corespunzător. Rulând pe mai multe noduri, este nevoie să tratăm fiecare excepție cu grijă.
În cazul în care nu sunteți dezvoltatori și nu știți nici un limbaj de programare nu înseamnă că nu puteți să vă definiți operațiile de Map și Reduce. Prin folosirea Pig si Hive orice persoană fără cunoștințe de programare poate să îți definească propriile reguli.
Hive se bazează pe un limbaj numit HiveQL. Acesta este extrem de asemănător cu SQL. Iar tot ce trebuie să facă o persoană este să își definească un query de felul:
SELECT * FROM CARS WHERE type = "BMW" AND value > 30000Hive se va ocupa de translatarea acestui query în job-uri pe care Hadoop poate să le execute.
Pig este destul de asemănător cu Hive. Acesta folosește un limbaj propriu denumit PigLatin. PigLatin este un limbaj simplu, cu operații precum FOREACH, comparare de valori și funcții de SQL precum MAX, MIN, JOIN, etc. Acesta translatează comenzile pe care le primește în comenzi de tip MapReduce.
Ambele sisteme sunt ușor de folosit și de optimizate. Pentru cei care nu sunt dezvoltatori, folosirea la Pig sau Hive este o opțiunea mult mai bună decât învățarea unui limbaj de la zero.
În ultimele trei articole din această serie am descoperit lumea Hadoop. Cum poate să stocheze și să proceseze un volum atât de mare de date. Tot ce ne-a mai rămas de făcut este să facem următorul pas și să începem să îl folosim.
Vă urez succes!
de Dan Suciu
de Ovidiu Mățan









